
XpertAI 3.6 is officially live! This release comprehensively streamlines every stage from knowledge pipeline creation, orchestration, authorization, publishing to knowledge base operations, enabling teams to visually build a reliable knowledge production line. Meanwhile, the plugin system is now a native capability of the pipeline, helping you quickly integrate external data sources and document processing tools via system integration or marketplace plugins.
Three Creation Paths: Build Your Pipeline in Seconds
- Blank Knowledge Pipeline: Freely orchestrate nodes from scratch, designing data processing strategies tailored to specific business processes.
- Built-in Templates: Optimized configurations for common scenarios like general documents and rich media PDFs, ready to run upon installation.
- Import Pipeline: Export existing pipelines as YAML and import them into other workspaces for rapid team reuse of best practices.
No matter which method you choose, the knowledge pipeline defines data sources, processing nodes, storage configuration, node connections, and optional user input forms, ensuring an integrated workflow.
Visual Orchestration: Full-Chain Upgrade from Document Data Source to Knowledge Base
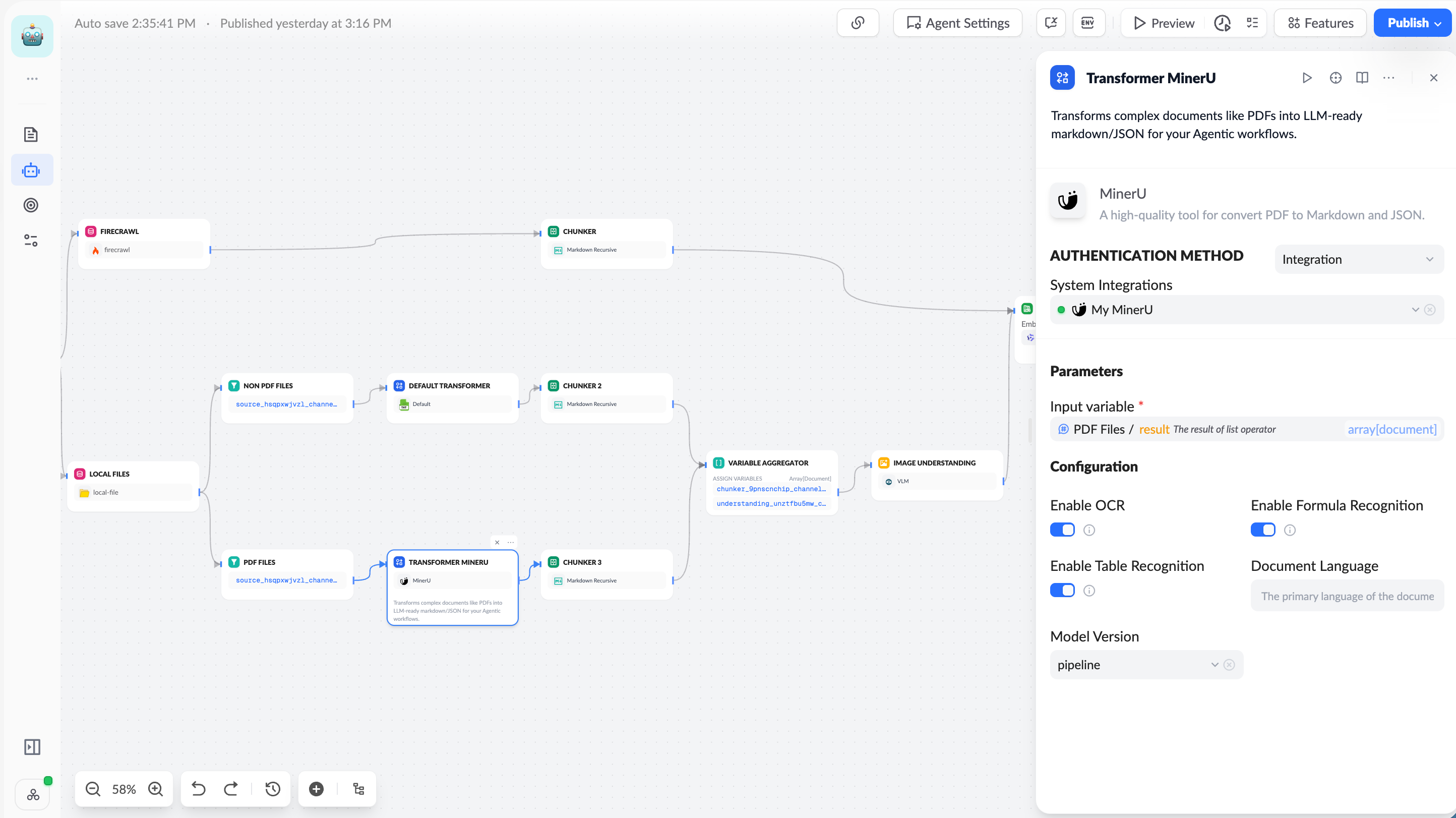
The new orchestration interface centers on the main path of "Document Data Source → Document Transformer → Chunker → Knowledge Base Node → Trigger". You can drag nodes, connect flows, and view parameter settings for each stage.
- Multi-source Data Input: Local files, online documents, cloud drives, web crawlers, and more can be connected in parallel, with additional extensions available in the plugin marketplace.
- Upgraded Document Transformers: Built-in transformers support text and image extraction from PDF, PPTX, DOCX, etc., and you can also use third-party transformers like Unstructured and MinerU from the plugin marketplace.
- Hierarchical Chunking System: The new Parent-Child Tree Chunker saves context in a tree structure, enabling parent block semantic recall and precise child block matching; generic chunkers and the Q&A Processor (in development) cover standard text and Q&A knowledge.
- Trigger Nodes: Customize runtime input parameters, dynamically passing variables such as delimiters or URLs when uploading or calling APIs.
Document Data Source Authorization: Dual Track with Environment Variables and System Integration
To ensure secure external data access, version 3.6 provides a unified authorization mechanism:
- Default Environment Variables: Pre-set API Keys during deployment, automatically used at pipeline runtime without manual binding.
- System Integration Center: Configure API Keys or future OAuth information centrally in the console, with authorization status synced back to the pipeline interface.
The current version supports API Key and OAuth (in development) authorization for Firecrawl and Feishu Docs, with more cloud document and drive services to be added.
One-Click Publishing to Sync with the Digital Expert Ecosystem
As part of the digital expert capabilities, the knowledge pipeline shares the same publishing experience as expert publishing. After publishing, you can:
- Directly enter the document list to upload or sync data;
- Browse the auto-generated API documentation for external system integration;
- Download as a pipeline template for reuse in other knowledge bases (in development).
Upload & Processing Experience: Preview Segments, Track in Real Time
After publishing, you can execute the new upload process in the document list:
- Select local files, remote file systems, cloud documents, or web crawling sources according to pipeline configuration;
- If trigger parameters are defined, fill in variables during upload and preview the segmentation effect;
- Track parsing, chunking, and embedding status in real time via progress bar, and jump directly to document details upon completion;
- For quick experiments, you can switch to basic configuration mode to upload files directly at any time.
Operations & Optimization: Continuous Knowledge Base Management
Version 3.6 offers more management entry points on the knowledge base side:
- Return to the pipeline editor to adjust node configurations or optimize strategies;
- Perform recall tests, update files, manage tags and descriptions on the knowledge base page;
- Expand knowledge base capabilities by obtaining new data sources or processing nodes from the plugin marketplace.
Plugin System: Connect to Infinite Extensions
With the GA release of the plugin system in 3.6, pipeline nodes are deeply integrated with the plugin ecosystem. Developers can:
- Browse official or community plugins in the marketplace to quickly connect to data sources like Firecrawl and Feishu Docs;
- Write custom plugins to extend enhancement points such as
Document Source,Document Transformer,Chunker, orImage Understanding; - Use system integration to centrally manage keys and OAuth information, ensuring security for multi-team collaboration.
For more on the plugin system design philosophy, see our previous Plugin System Launch introduction.
XpertAI 3.6 Knowledge Pipeline makes knowledge-driven agent building more efficient, standardized, and extensible. Log in to the cloud platform now to experience the new templates, hierarchical chunking, and plugin ecosystem upgrades!