Maintaining Documents
Knowledge Base Documents refer to various types of textual information resources stored in the system. These can be files in formats such as PDF, Word, or Text, or web page content, providing efficient query and learning materials for intelligent agents. The document management function is one of the core components of the knowledge base, enabling users to upload, categorize, retrieve, and manage document content, ensuring the system can quickly and accurately extract relevant information from a large volume of documents.
Managing Documents
In the knowledge base document management list, users can conveniently perform a series of operations on documents, including adding, converting to embeddings, deleting, and configuring chunking settings:
Adding Documents: Users can upload documents in various formats to the system, supporting multiple document types (e.g., PDF, Word, Text, etc.).
Converting to Embedded Documents: To improve retrieval efficiency, users can convert document content into embeddings. Through this process, the information in the document is transformed into vector form, allowing the system to perform semantic searches and relevance matching more effectively.
Deleting Documents: Users can delete documents that are no longer needed to keep the knowledge base organized. The deletion takes effect immediately, removing the document content from the system.
Document Chunking Settings: Users can individually configure chunking methods for documents, splitting them into smaller segments for easier management and querying. This chunking setup enhances the system’s processing speed and accuracy, especially during large-scale information retrieval.
Adding Documents
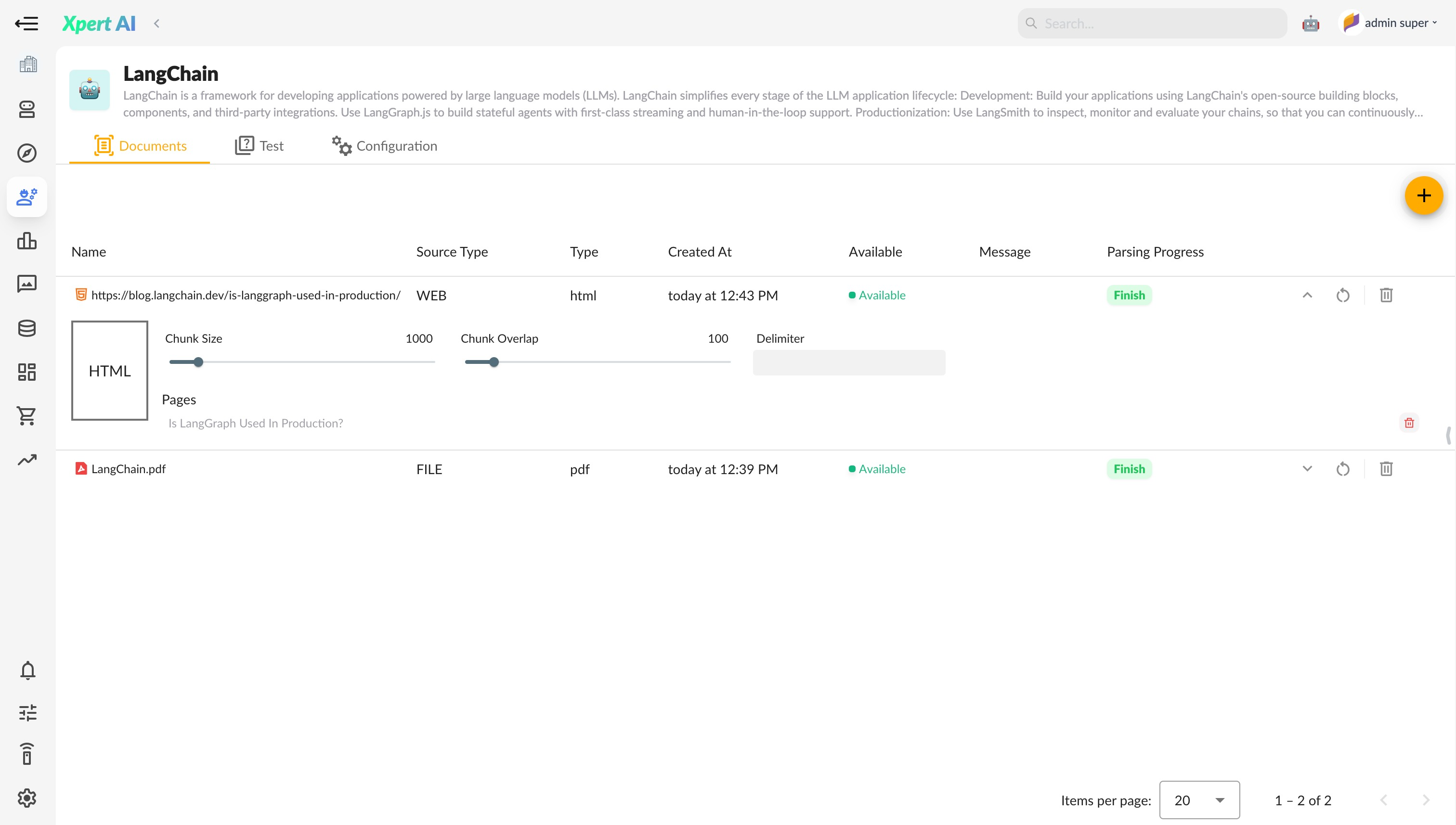
The XpertAI knowledge base provides a document upload function, allowing users to upload documents in two ways:
Uploading Local Files: Users can directly upload local files. Supported formats include TXT, Markdown, PDF, HTML, XLSX, PPTX, CSV, and other common formats. Each file size is limited to no more than 15MB.
Web Scraping: Users can also choose to upload documents by scraping text from web pages. This is useful for extracting information from websites to further enrich the knowledge base.
Files
After uploading files, users can click to preview the document content. For files with large amounts of data, only the beginning portion is previewed. Before creating a document from uploaded files, users can still delete unnecessary ones.
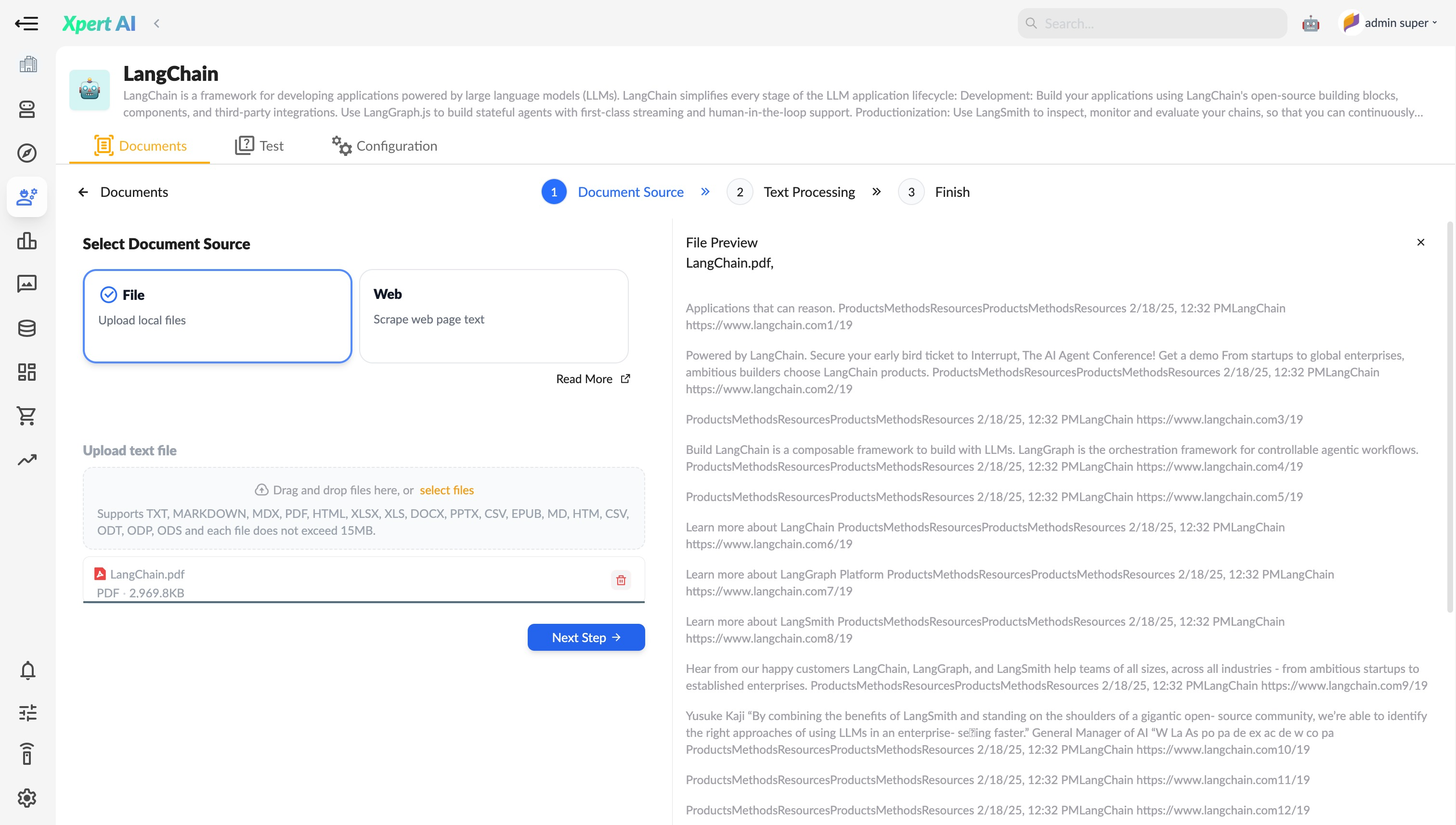
Web Pages
Scraping online web pages supports two tools: Playwright and Firecrawl.
- Playwright scrapes web content through a local server.
- Firecrawl scrapes web content via an integrated connection with the Firecrawl provider.
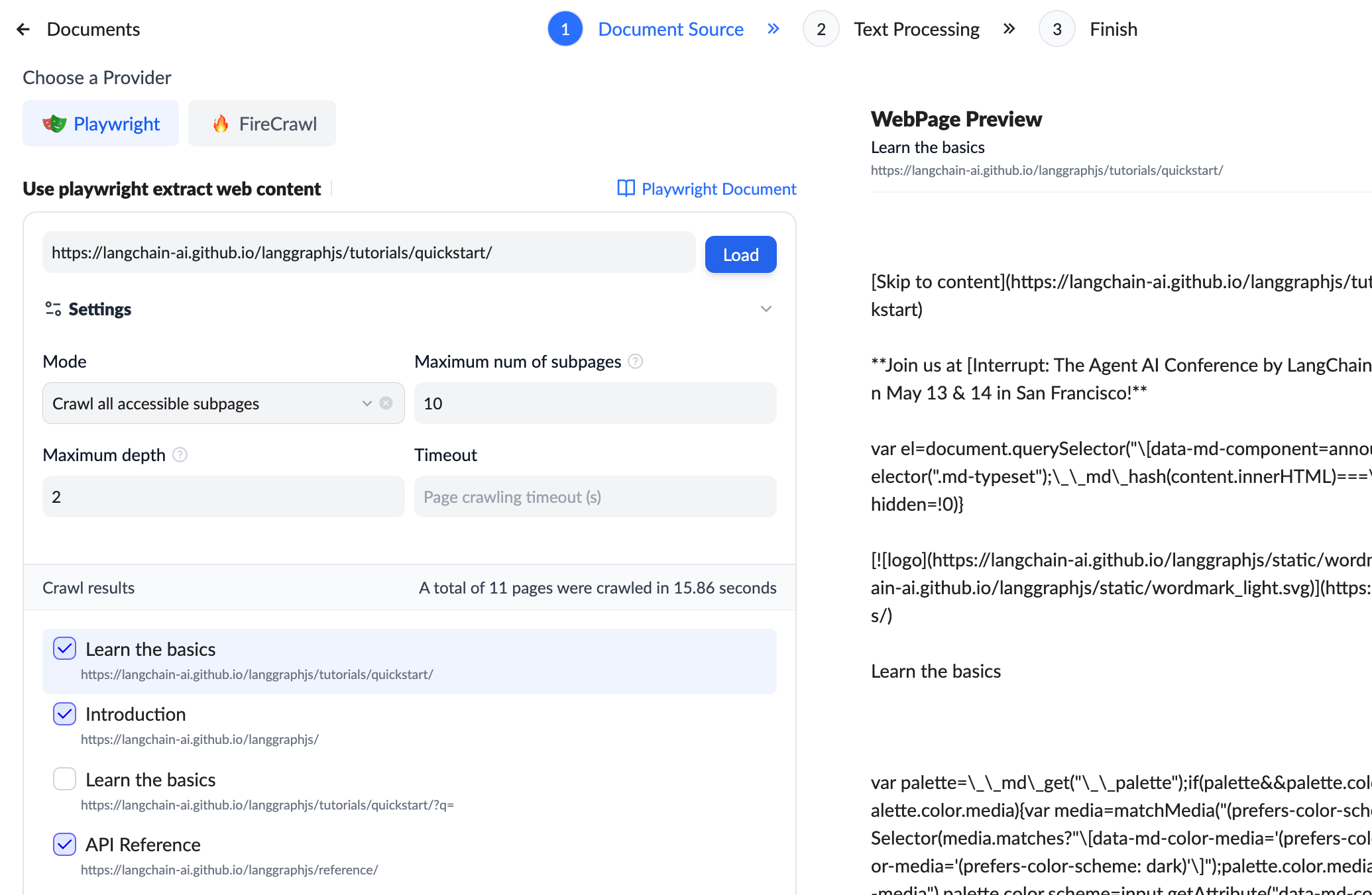
Playwright Operation Steps:
Enter the full URL of the target web page in the input box (e.g., https://mtda.cloud/), and click "Load" to view the web scraping results below. Click "Preview" to see the web content. Click "Next" to configure it the same way as local documents, then save and process.Firecrawl Operation Steps:
Unlike Playwright, you first need to configure an integration connection.
Steps to Configure Integration Connection:
In the settings page at the bottom left corner, find the integration link and add a new Firecrawl integration connection. First, customize a name. You’ll also need an API Key—click "Get an API Key" on the page to jump to the Firecrawl website, register, obtain your API Key, then copy and fill it in.
Web Scraping Steps:
After configuring the integration connection, go to the scraping page interface, select the configured connection, enter the URL, and choose the scraping mode and maximum subpages. Click "Load" to scrape the web content. Then click "Next" and "Save" to create a new document.
Chunking Settings
- Delimiter: Users can specify a custom delimiter to split text into smaller chunks. The default delimiter is automatically recognized based on the text structure, but users can adjust it as needed.
- Chunk Size: Users can set the number of characters per chunk (default is 1000 characters). The chunk size determines the length of each text segment, affecting retrieval precision and efficiency.
- Chunk Overlap: Users can set the number of overlapping characters between adjacent chunks (default is 100 characters). Overlap helps maintain contextual continuity and reduces information fragmentation.
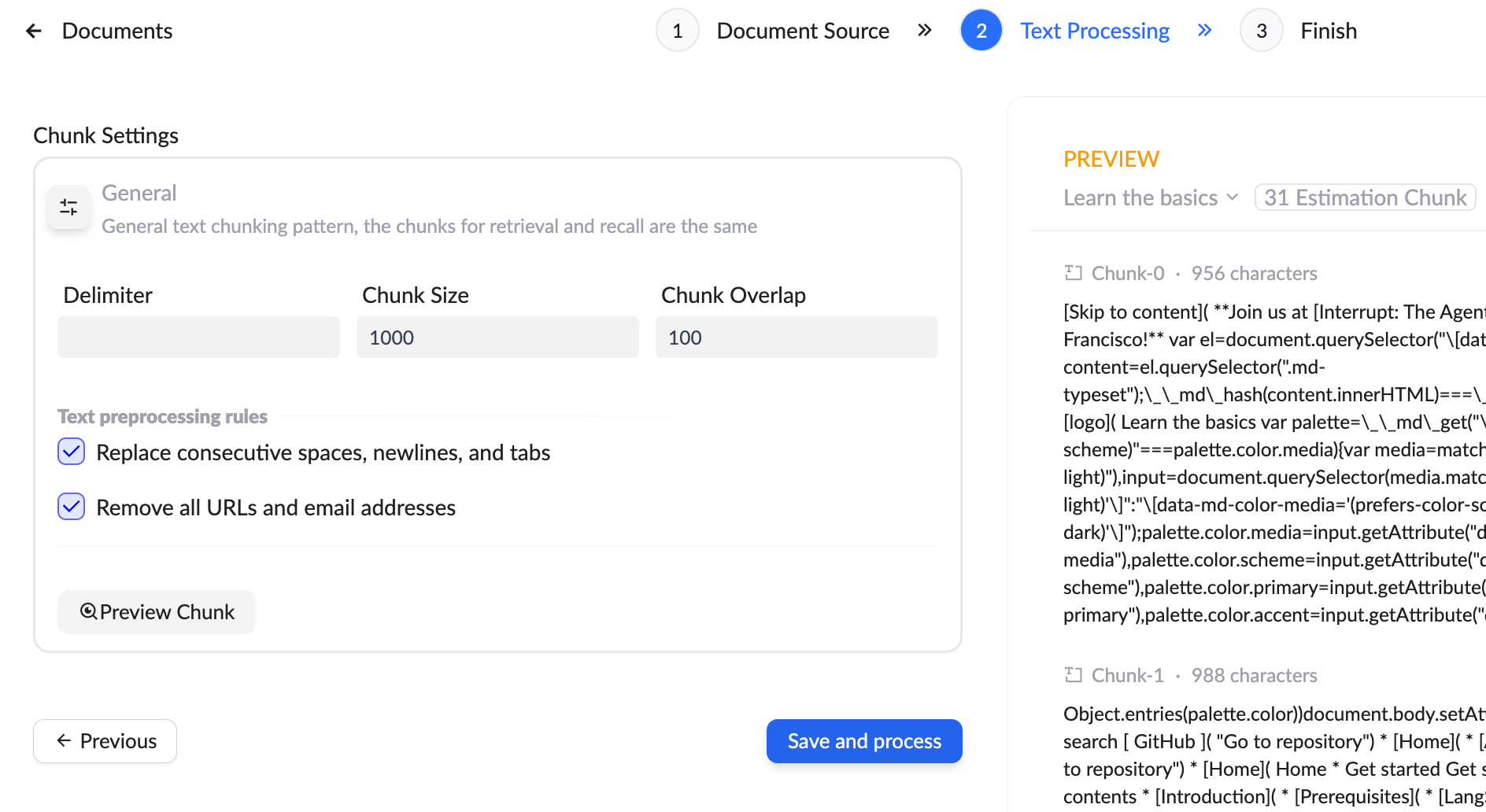
Before chunking, XpertAI provides powerful text preprocessing features to ensure the input content is clean and structured. Users can enable the following options:
Replace Consecutive Spaces, Line Breaks, and Tabs: Remove redundant whitespace characters to standardize the text format.
Remove All URLs and Email Addresses: Protect privacy and keep content concise, ideal for documents requiring noise reduction.
Preview Function: Using the "Preview Chunk" button, users can view the chunked text in real-time. The preview window displays the character count and content of each chunk, helping users verify if the settings meet their needs.
Example: The preview might show results like “Chunk-0 - 956 characters” or “Chunk-1 - 988 characters,” allowing users to adjust parameters based on the actual content.
Best Practices
- Chunk Size Recommendation: For complex documents, set a larger "Chunk Size" (e.g., 1000-2000 characters) to preserve context; for short queries, smaller chunks (e.g., 500 characters) may be more suitable.
- Overlap Setting: Keep "Chunk Overlap" between 50-150 characters to balance contextual continuity and performance.
- Preprocessing Optimization: If a document contains significant formatting noise (e.g., excessive line breaks or URLs), enable preprocessing rules to improve chunking quality.
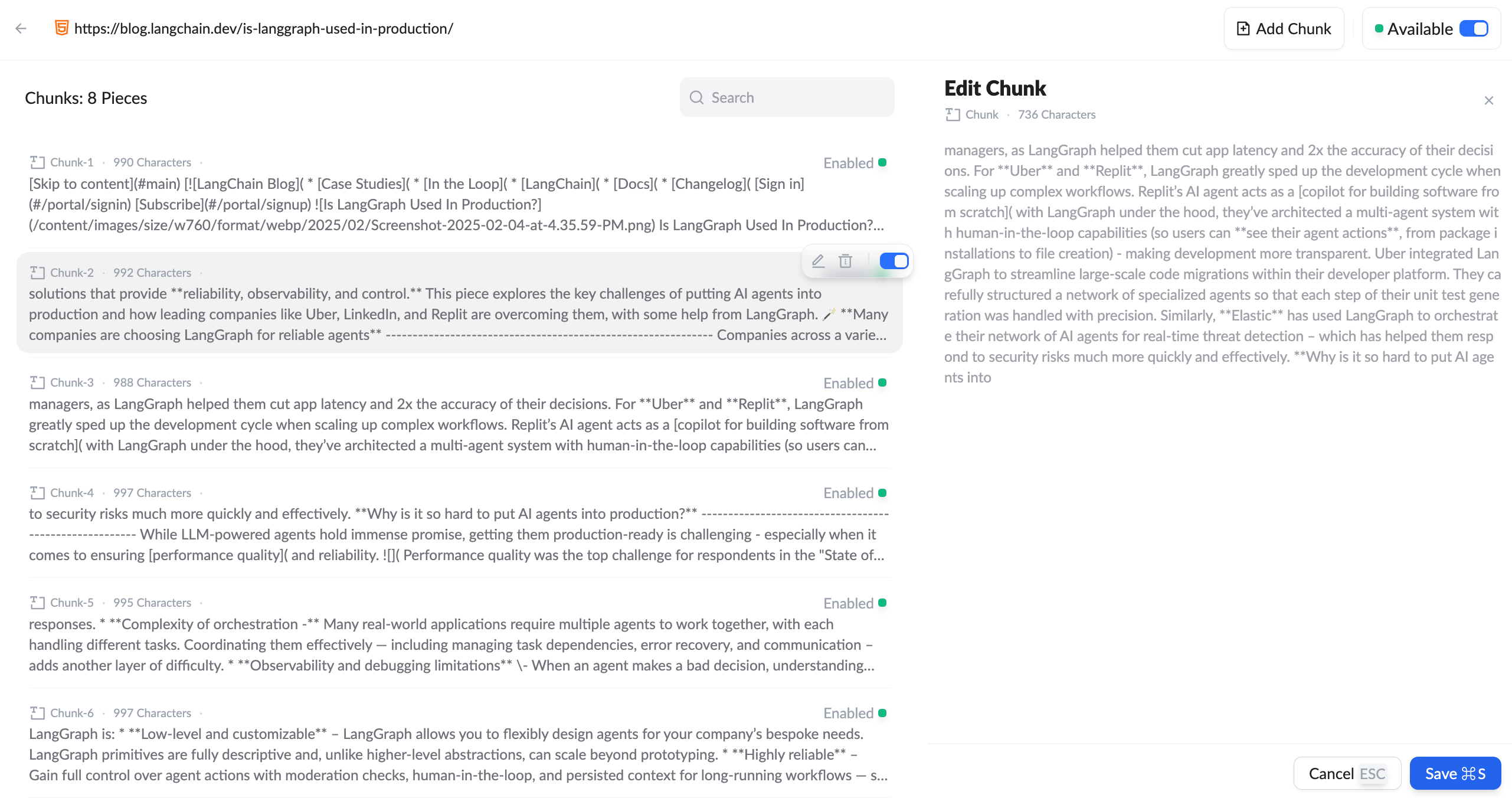
Managing Chunks
- Chunk Viewing and Status Management: Each chunk is presented in a concise card or list item format, including features like chunk number and character count, content preview, enable/disable status, and editing options.
- Editing Chunks
- Adding New Chunks
- Search and Filtering
How to Use the Knowledge Base
On the agent page, create a new digital expert, add a knowledge base, and connect them. This allows the digital expert to retrieve content from the knowledge base.
After establishing the connection, you can test it by clicking "Preview" and sending a question. From the conversation log, you can see that the AI’s response invokes the Knowledge Retriever to fetch text from the knowledge base. Once the content is retrieved, it’s passed to the large language model (LLM).
The large language model then answers the user based on the retrieved content.