步骤二:知识流水线编排
在 XpertAI 中,知识流水线就像是一条智能化的数据处理生产线。每个节点都承担特定任务,你可以通过拖拽和连接不同节点,将原始文档数据一步步转化为可检索、可理解的知识库内容。 整个过程高度可视化、可配置化,帮助你快速构建符合业务逻辑的知识获取与索引流程。
通过本章节,你将了解知识流水线的整体流程,理解不同节点的作用与配置方式,从而自定义并优化知识处理链路。
界面状态说明
进入知识流水线编排界面时,你会看到:
- 标签页状态:Documents(文档)、Retrieval Test(召回测试)和 Settings(设置)标签页处于灰色不可用状态。
- 前置要求:需完成知识流水线的配置、调试与发布后,才能上传文件并进行召回测试。
如果你选择空白知识流水线,系统将默认展示仅包含“知识库节点”的空白画布。你可根据引导逐步创建和连接其他节点。
若选择预设流水线模版,画布中会直接显示该模版的完整节点结构。
知识流水线总体流程
在正式配置前,我们先理解知识流水线中数据的流转过程:
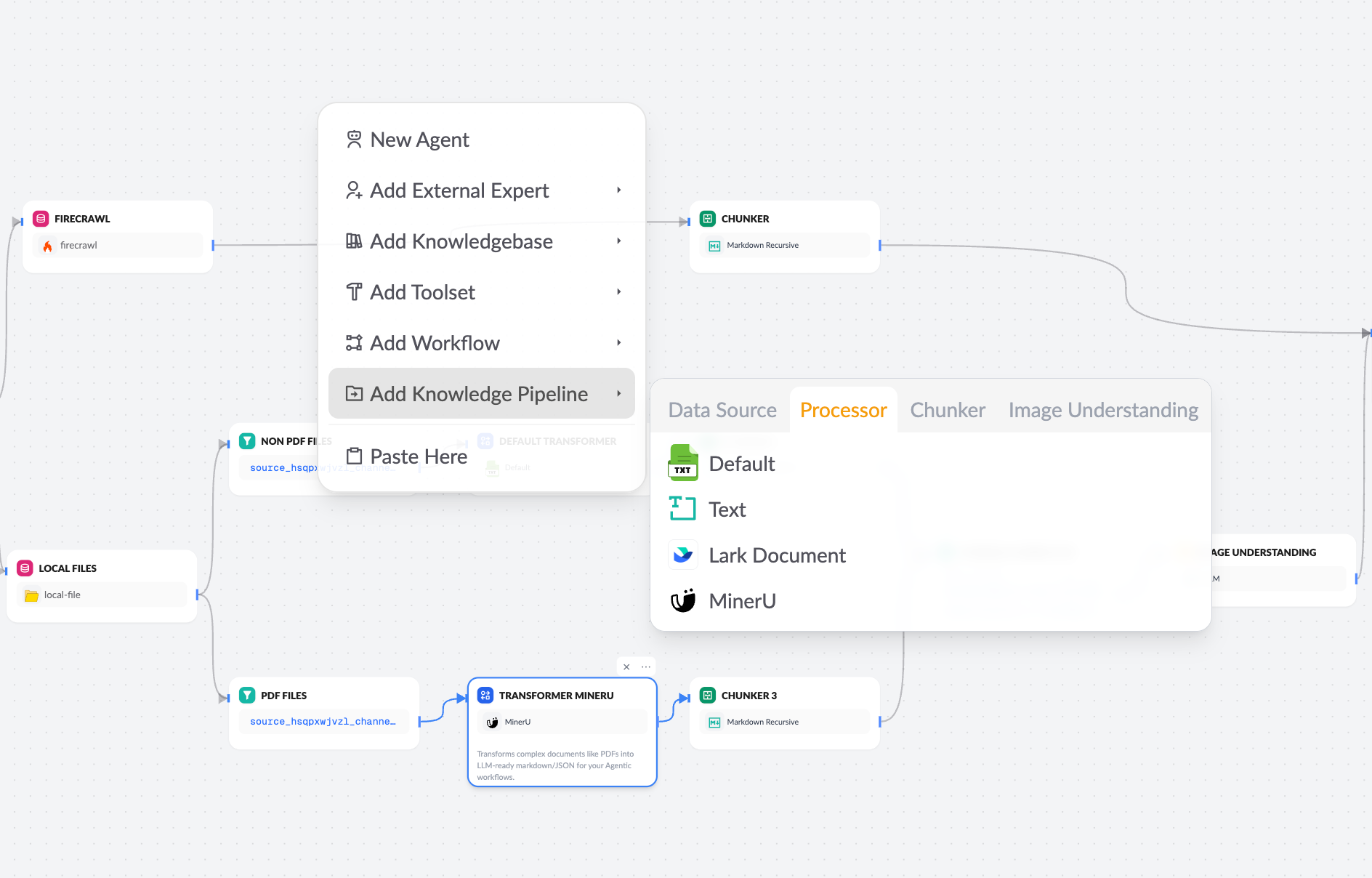
- 数据源配置:导入原始内容(本地文件、Notion、网页、网盘等)。
- 文档转换节点:将原始文件转换为标准化结构数据(支持文本与图片提取)。
- 分块处理节点:对结构化内容进行智能分块,生成适合索引的内容片段。
- 知识库节点:定义树状结构与索引策略。
- 触发器节点配置:设定输入参数,以便触发流水线运行。
- 测试与发布:验证处理流程后正式启用知识库。
步骤一:数据源配置
在 XpertAI 中,你可以同时选择多个数据源进行知识提取。每个数据源都可独立配置参数,支持本地上传、在线文档和网页爬取等形式。
目前支持的数据源包括:
- 本地文件上传
- 在线文档(如 Notion)
- 在线网盘(Google Drive、Dropbox、OneDrive)
- 网页爬虫(Firecrawl 等)
更多数据源可通过 XpertAI 插件市场(Plugin Marketplace)获取。
步骤二:配置数据处理节点
数据处理节点是知识流水线的核心。它负责将原始文件解析、转换、清洗并分块,形成结构化语义单元。 XpertAI 的数据处理分为两大部分:文档转换器(Document Transformer) 与 分块器(Chunker)。
文档转换器 (Document Transformer)
文档转换器负责将 PDF、Word、Excel 等多种格式文件转化为可供模型理解的结构化内容。 它支持图片、表格、文本等多模态内容的抽取,是知识流中的“第一道工序”。
你可以选择 XpertAI 内置转换器 或 插件市场(Marketplace) 中的其他转换器(如 Unstructured、MinerU 等)。
特点
- 支持多格式输入(PDF、DOCX、XLSX、PPTX、TXT、Markdown 等);
- 自动提取图片并生成可用的 URL;
- 支持异步任务和批量转换;
- 支持 OCR 与结构化表格抽取。
分块器 (Chunker)
文档经过转换后,仍然过于庞大,无法直接用于向量化与检索。分块器将内容拆解为语义完整的小块(Chunk),以便后续索引与召回。
XpertAI 提供多种分块策略,包括:
| 类型 | 特点 | 适用场景 |
|---|---|---|
| 通用分块器 | 固定大小分块,支持分隔符与重叠 | 通用文本 |
| 父子分块器 | 自动生成树状上下文结构 | 长文档或章节结构复杂文档 |
| 问答处理器(Q&A Processor) | 提取问答型数据,如FAQ或Excel问答表 | 表格或结构化问答数据(开发中) |
通用分块器
配置项说明
| 参数 | 说明 |
|---|---|
| 分隔符 (Delimiter) | 按换行或自定义正则拆分段落 |
| 最大分块长度 (Max Length) | 超出长度自动二次分割 |
| 重叠长度 (Overlap) | 提升上下文关联性 |
输入输出
| 类型 | 名称 | 说明 |
|---|---|---|
| 输入 | Document | 原始文本内容 |
| 输出 | Document with chunks | 分块后的语义块数组 |
父子分块器
父子分块器生成了 Tree 结构的分块树(Parent-Child Tree),这是 XpertAI 独创的分块体系,统一管理父子块之间的层级关系。
与传统的“分段结构(Chunk Structure)”不同,XpertAI 采用树状结构存储分块,支持任意层级的溯源与聚合。
特点
- 自动维护上下文关联;
- 支持父块语义检索与子块精准匹配;
- 可扩展为混合图谱(Graph Structure)。
问答处理器 (Q&A Processor) — 开发中
问答处理器融合了提取与分块功能,用于从 CSV 或 Excel 中抽取问答对(Question / Answer)。 该节点目前处于开发阶段,将支持结构化问答型知识的批量处理。
步骤三:配置知识库节点
知识库节点是流水线的终点,负责构建可检索的知识索引结构。
XpertAI 的知识库采用 树状分块结构(Tree Structure) 管理分块层级,每个节点(Chunk)都可关联向量、图片、来源信息及上下文节点。
核心特性
| 模块 | 描述 |
|---|---|
| 结构 | 统一的树状分块结构 |
| 索引 | 向量索引(Vector Index) |
| 检索 | 基于语义相似度的召回机制 |
| 关键词索引 | 开发中,预计支持混合检索模式 |
步骤四:配置触发器节点(用户输入参数)
在 XpertAI 中,用户输入参数通过 触发器节点(Trigger Node) 来实现。
触发器节点允许你定义流水线运行的输入参数(如上传文件、URL、分隔符、自定义变量等),这些参数将在运行时注入到上游节点。
优势
- 统一参数管理;
- 与其他节点自动绑定;
- 可视化配置与默认值支持。
步骤五:测试与发布
完成流水线配置后,你可以点击右上角的 测试运行(Test Run) 按钮来验证整个流程。 系统会依次执行每个节点的任务,并输出最终知识库结果。
测试通过后,点击 发布(Publish) 即可将知识流水线正式应用于你的知识库。
总结
XpertAI 的知识流水线将数据处理、分块管理、索引构建整合为一体化架构:
Trigger (Runtime Inputs) → Data Source → Document Transformer
→ Chunker (Tree Structure)
→ Image Understanding (vlm/ocr)
→ Knowledgebase (Vector Embedding)
这种体系不仅简化了知识库的构建,还确保了跨文档一致性、上下文可追溯性和检索性能的最大化。