增强功能
增强功能可以提升数字专家使用者的交互体验。例如添加文件上传入口、给 LLM 应用添加一段自我介绍或使用欢迎语,让应用使用者获得更加丰富的交互体验。
点击应用右上角的 “功能” 按钮即可为应用添加更多功能。
增强功能详解
1. 对话开场白(Welcome Message)
“对话开场白”用于在数字专家欢迎页面展示一段自定义文案,可作为欢迎语或 AI 自我介绍,帮助用户快速了解助手的能力与用途。
🎯 主要作用
- 拉近与用户的距离,营造亲切感
- 引导用户提问,降低使用门槛
- 交代应用背景,提高对话效率
⚙️ 配置方式
- 自定义欢迎语内容(支持换行和表情符号)
- 可设置 1~10 个开场建议问题
- 建议问题以按钮形式展示,点击可快速提问
💡 使用建议
- 欢迎语尽量简洁友好,例如:
“你好,我是您的数据分析助手,可以帮您分析销售、库存或预算情况。”
- 建议问题可围绕常见需求设置,如:
- “查看本月销售数据”
- “分析客户流失原因”
- “生成财务报表摘要”
2. 问题建议(Suggested Questions)
“问题建议”用于在每轮对话结束后,智能生成 5 个相关的后续问题,引导用户继续提问,保持对话活跃。
🎯 主要作用
- 延续用户兴趣,提升互动体验
- 激发灵感,降低“无话可问”的门槛
- 提供创意话题,增强对话趣味性
⚙️ 配置方式
- 编辑提示词模板,引导大模型生成合适的问题
- 支持自由设定语气,如:专业、轻松、幽默等
- 模板内可加入场景说明或指令
💡 使用建议
结合应用目标和用户偏好设定提示词,例如:
“请根据用户刚才的提问,生成 5 个风格幽默、富有想象力的问题,鼓励继续探索。”
示例输出问题(风格幽默):
- 如果 AI 有梦想,它的职业理想会是什么?
- 为什么键盘的“F”键总是比“J”键酷?
- 要是猫统治了人类社会,第一条法律会是什么?
- 时间旅行的最大 bug 会是什么?
- 如果明天没有周一了,会发生什么?
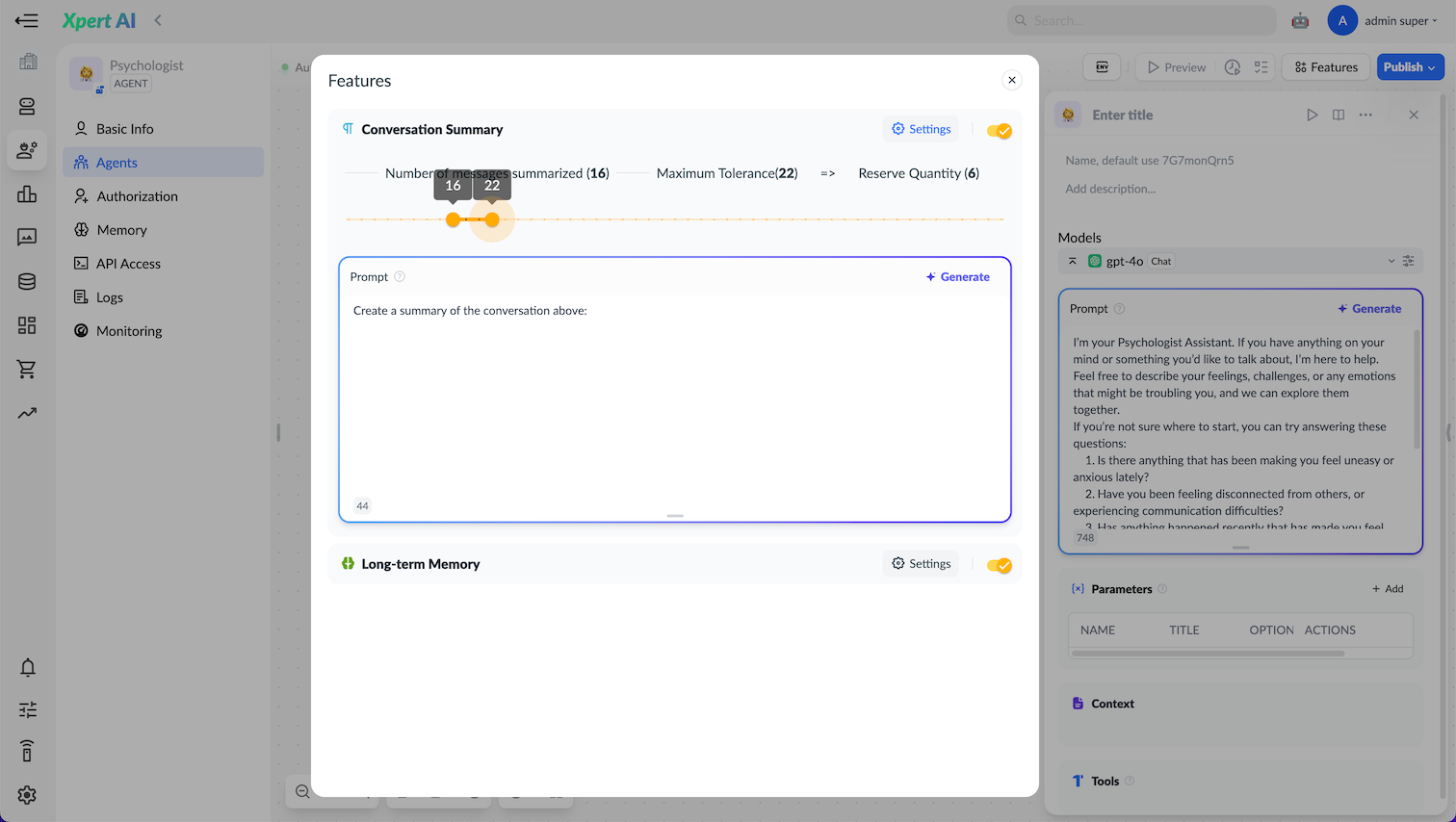
3. 会话总结(Conversation Summary)
当对话消息数量超过设定的最大容忍数量(如 100 条)时,Xpert 会通过“会话总结”功能,将历史对话中的重要信息进行提炼,转化为简明摘要,以减轻系统记忆负担,并提升后续对话的聚焦度和效率。
🧠 工作机制
- 最大容忍数量 (Maximum Tolerance): 设置在开始生成新摘要之前,允许新对话消息超出“数量”的上限值。例如图中显示为 22。这意味着即使对话超过了 16 轮,系统也会继续记录,直到达到 22 轮,才会触发新的摘要生成。这个参数有助于避免频繁生成摘要,从而减少计算开销。
- 总结的消息数量: 将要总结的消息数量,例如图中的 16 表示将会总结会话中22个消息中的最开始的 16 条消息。
- 保留数量 总结消息后保留下来的消息数量,例如图中的 4 表示保留 4 条消息,其余的消息将被删除(以摘要的形式出现在系统提示词中)。
- 提示词:用于指导系统如何概括对话中历史消息,未提供则系统使用默认的提示词。
示例配置: 最大容忍数量:100 总结触发数量:40 👉 保留数量 = 100 - 40 = 60 条信息
📋 应用场景
- 用户与智能体长时间交互
- 多轮复杂任务跟进
- 需要阶段性知识总结或任务回顾的对话流
4. 长期记忆(Long-term Memory)
参见 长期记忆 文档。
5. 记忆回复(Memory Reply)
记忆回复功能允许为智能体手动编辑并存储特定的问答式记忆,系统在用户提问时可优先匹配这些“记忆”内容,直接生成高质量、稳定、可控的回复,跳过 LLM 的自由生成过程。 此机制有效提升了问答一致性与可靠性,特别适用于定制化、规则明确或幻觉敏感的场景。
🧠 工作机制
- 问答记忆创建:开发者可为智能体人工编写若干问答对(问题+标准答案),作为 长期记忆 内容。
- 相似度匹配:当用户提问时,系统使用 Embedding 向量计算用户输入与所有记忆问题的相似度。
- Score 阈值判断:只有相似度分数 ≥ 设置阈值,系统才会召回并直接返回相应记忆中的首个回答。
- 嵌入模型:采用长期记忆配置的 Embedding 模型,若未设置则使用系统全局默认的模型。
⚙️ 配置参数说明
| 参数项 | 说明 |
|---|---|
| Score 阈值 | 控制记忆是否被召回的相似度分数界限(如 0.85) |
| Embedding 模型 | 采用长期记忆配置的 Embedding 模型 |
📌 应用场景
- ✅ 特定领域的标准化回复
适用于企业、政府、教育、金融等领域知识库场景,对部分问题需精准控制回答,如:- “公司客服电话是多少?”
- “我可以删除我的账户吗?”
- “本系统是否支持海外用户?”
这些问题通常应有明确结果或应避免生成幻觉内容。
- ✅ 快速原型(POC/DEMO)构建
在 POC 或 DEMO 阶段,通过人工录入问答记忆可快速调优产品性能,实现客户预期。
- ✅ 与 RAG 并行作为稳定 fallback
记忆回复机制相当于一套轻量级、可控的检索增强系统(RETRIEVAL ONLY),有效规避大模型生成过程中的幻觉或答非所问问题。
✨ 功能优势
- 🎯 提升答案稳定性与确定性
- 💡 避免大模型自由生成带来的幻觉问题
- 🧩 支持与知识库、搜索等模块并行使用
6. 总结标题(Conversation Title)
总结标题功能用于在用户首次发起会话后,根据会话内容自动提炼出一个简洁、概括性的标题,作为该轮对话的会话标题。该功能可增强多轮会话的可浏览性与组织性,尤其适用于智能体聊天记录较多的场景。
| 配置项 | 描述 |
|---|---|
| 是否开启 | 默认为开启,系统将自动为每轮新会话生成标题 |
| 标题提示词 | 支持配置提示词(Prompt),引导大模型以指定风格或格式生成摘要标题 |
系统会在用户发送首条消息或系统识别到对话初步成型后,自动触发标题生成逻辑。
🧩 示例
| 会话内容 | 自动生成标题 |
|---|---|
| “我想了解我们销售部门上个月的业绩,能按地区分一下吗?” | 销售部门上月业绩分析 |
| “能不能帮我写一个 AI 助理功能的介绍文案?风格轻松一点。” | AI 助理功能文案撰写请求 |
| “请解释一下记忆回复机制的原理和应用场景。” | 记忆回复机制解析 |
🛠️ 配置建议
对于结构化对话场景(如 BI 问答、工单系统),建议结合用户意图或实体字段定制提示词生成标题。
提示词应尽量引导生成 简洁、具体、无多余词汇 的标题,例如:
总结一句话标题,用于标记本次用户提问的主题,避免冗余词汇。
7. 文件上传(File Upload)
文件上传功能允许用户在对话过程中上传指定类型的文件,将图片或完整文本插入到当前对话中,辅助 AI 更好地理解和响应上下文问题。
✅ 功能说明
上传位置: 在对话框中,用户可通过点击📎图标(或“上传一个文件”按钮)上传文件。
上传后效果: 文件内容(如文档文本、图片等)会作为用户消息注入到上下文中供模型参考,提高对话理解精度。
⚙️ 配置项
- 最大上传数量
- 设置值范围:1 ~ 任意值
- 含义:限制用户单次可上传的文件数量
- 示例配置:最大上传 10 个文件
- 文件大小限制(按类型区分)
| 文件类型 | 最大单文件大小 |
|---|---|
| 文档 document | 15MB |
| 图片 image | 10MB |
| 音频 audio | 50MB |
| 视频 video | 100MB |
- 支持文件类型
支持上传以下类型的文件,便于大模型理解和解析:
- 文档:
TXT,MD,MDX,MARKDOWN,PDF,HTML,XLSX,XLS,DOC,DOCX,CSV,EML,MSG,PPTX,PPT,XML,EPUB - 图片:
JPG,JPEG,PNG,GIF,WEBP,SVG - 音频(如开启):
MP3,M4A,WAV,AMR,MPGA - 视频(如开启):
MP4,MOV,MPEG,WEBM
支持文件类型可通过界面勾选配置,非勾选类型将禁止上传。
8. 文字转语音(Text to Speech)
文字转语音(TTS)功能支持用户在 AI 生成回答后,通过点击朗读按钮将回答内容转换为语音并播放。该功能提升了 AI 对话系统的可访问性与多模态交互能力,特别适用于移动端场景、视力不便用户、阅读压力较大的信息型对话场景等。
⚙️ 功能说明
| 配置项 | 描述 |
|---|---|
| TTS 模型选择 | 可配置不同的 TTS 模型(如 Azure TTS、Google TTS、Edge-tts、本地 TTS等) |
| 模型参数配置 | 支持配置音色(Voice)等参数 |
| 播放触发方式 | 用户点击朗读按钮后触发播放,支持播放/停止操作 |
| 多语言支持 | 只要模型支持,即可自动适配不同语言的文本朗读 |
9. 语音转文本(Speech to Text)
语音转文本(STT)功能允许用户在对话框中通过语音输入代替文字输入。当启用该功能后,用户点击麦克风按钮即可开始录音,浏览器将捕捉用户的语音内容结束后转化为文字,作为提问内容发送给 AI。
| 配置项 | 描述 |
|---|---|
| 启用方式 | 用户点击对话输入框中的麦克风按钮,即可开始语音输入 |
| 浏览器权限 | 需用户授权麦克风使用权限(通常首次会弹出授权提示) |
| STT 模型支持 | 可集成本地浏览器识别(如 Web Speech API),或外部 STT 服务(如 Whisper、Azure STT) |
| 识别语言配置 | 可预设识别语言(如中文、英文等),提高转写准确率 |
🔒 隐私与安全说明
- 所有语音内容仅用于识别用途,不被存储或分析(除非用户明确授权)
- 浏览器会提示请求使用麦克风权限,用户可随时关闭
📚 常见问题 FAQ
❓1. 功能启用后不生效?
可能原因及排查建议如下:
| 原因 | 排查与解决方案 |
|---|---|
| 功能未保存 | 在启用功能后,配置尚未自动保存。 |
| 配置项不完整 | 某些增强功能(如记忆回复、TTS等)需配置模型或参数,如未配置则不会生效。请检查是否漏填。 |
| 网络异常或服务依赖问题 | 部分增强功能依赖外部服务(如 TTS/STT 模型、文件存储服务),建议检查网络连接或查看控制台日志是否有接口报错。 |
| 问题建议 | 只在发布后生效 |
❓2. 文件上传失败如何排查?
文件上传失败常见于以下几种情况:
| 问题类型 | 排查建议 |
|---|---|
| 上传大小超限 | 请确认上传文件未超过系统设置的大小限制(通常为 20MB 或管理员配置的限制)。 |
| 文件类型受限 | 目前仅支持上传常见文档类型(如 .pdf、.docx、.xlsx、.csv、.txt 等),请检查文件后缀是否受支持。 |
| 网络或服务器异常 | 检查浏览器控制台或网络面板是否有上传失败提示或 API 报错信息。 |
| 浏览器不支持多文件选择 | 请确保使用最新版 Chrome、Edge、Safari 等现代浏览器,避免使用兼容性差的浏览器。 |
| 上传后未绑定至上下文 | 上传成功后,需确保文件被系统绑定至对话上下文,否则不会参与 AI 生成过程。可尝试重新选择文件并确认文件状态。 |
❓3. 如何清空长期记忆内容?
长期记忆用于保存用户与数字专家的长期对话知识,适用于定制回复、上下文理解等高级场景。若需清空长期记忆,请按如下操作:
✅ 清空某个数字专家的全部长期记忆:
- 进入该数字专家的长期记忆管理界面
- 点击【清空记忆】按钮,系统将提示是否确认操作
- 确认后,该智能体的全部记忆条目将被删除,不可恢复
✅ 删除部分记忆条目:
- 同样在「记忆管理」功能界面
- 删除的条目,点击【删除】
- 也可使用关键词搜索后删除匹配内容
⚠️ 注意:
- 清空长期记忆不会影响短期对话历史
- 记忆清除后不可恢复,请谨慎操作
- 清除后系统将重新依赖基础模型生成回答,可能缺乏定制化内容